Pathery Dev Log #1: Performant Serverless Queries Without a Cluster
Exploring cost-effective alternatives to cluster-based search using AWS Lambda, EFS, Rust and Tantivy.

This is the first dev log for the Pathery project. Pathery is an open-source effort to demonstrate the feasibility of a true Serverless (e.g. usage based pricing) full-text search service using AWS primitives.
The straightforward approach of connecting Tantivy to AWS Lambda and EFS gets you pretty far and is is the approach currently taken by Pathery. However, this approach starts to show its cracks as the size of an index grows.
A search index in Tantivy is built up of many smaller immutable indexes called segments. As an index grows in size, the network latency of pulling its constituent segments to a query Lambda becomes a bottleneck to search speed. Fortunately, this only seems to be a problem on an initial query, a phenomenon I will refer to as a data cold start. Subsequent queries have significantly improved performance, presumably due to EFS caching magic behind the scenes.
In order for Serverless search to work, data cold starts need to return a response within a reasonable amount of time for a user. For the purposes of this post, lets consider that to be 1 second. It isn't hard to create an index that forces query times outside of this limit. The test data set for Pathery is just over 1 GB when indexed and searching this index takes >5 seconds during a data cold start.

We can do better…
One way to combat the data cold start problem is to fan out a query to multiple Lambdas. This should work because Tantivy builds an index by appending to an immutable log of segments where each segment is in index in and of itself. By fanning out, each Lambda could look at a small enough partition of the index segments to respond within a reasonable amount of time, even on a data cold start.
Unfortunately, Tantivy does not have an easy way to query individual segments by id, but it does give you the ability to supply your own implementation of the Directory trait for an index which Tantivy uses to abstract over the persistence layer. We can take advantage of this extension point to modify the index metadata file (meta.json) — which contains the list of the segment ids for an index — as it is retrieved from the Directory. By removing segments from meta.json, we can force Tantivy to look at a subset of the total index.
Before we get too excited and start coding up a solution around this, we should check our assumptions as cheaply as possible by forcing Tantivy to look at one and only one segment. If our assumptions about network latency are correct, querying one segment should return an incomplete response substantially faster than querying the whole index. Let's modify the atomic_read function for the PatheryDirectory to only return the last segment:
// ...
fn atomic_read(
&self,
path: &std::path::Path,
) -> Result<Vec<u8>, tantivy::directory::error::OpenReadError> {
let result = self.inner.atomic_read(path)?;
// check that we are returning meta.json
if path == Path::new("meta.json") {
// unpack meta.json into a structure we can manipulate
let mut meta: HashMap<String, serde_json::Value> =
serde_json::from_slice(&result[..]).unwrap();
// get the segments array
let segments = meta.get("segments").unwrap().as_array().unwrap();
// create a new array with just the last segment
let segments: Vec<_> = vec![segments.last().unwrap().clone()];
// replace the original array with our new one
meta.insert(String::from("segments"), serde_json::Value::Array(segments));
Ok(serde_json::to_vec(&meta).unwrap())
} else {
Ok(result)
}
}
// ...We use the last segment because it should be the smallest segment due to how segment merging works (more on this later). After deploying and running a test query, we can observe the data cold start query time decrease to ~250ms:

Fantastic, this idea has legs! But... there is a problem. Segments are not entirely immutable due to merging. Tantivy will merge segments periodically to reduce the total number of segments. By default, it uses a LogMergePolicy which creates segments that exponentially increase in size with newly indexed data forming the smallest segments that are eventually merged into larger segments. In the Pathery test index, there are 9 segments which we can see by listing the segment files that get created (this only includes .pos files for brevity, there are more files associated with each segment):
-rw-rw-r-- 1 1001 1001 40M Nov 29 00:06 1bfb3f7ef08e40b4bd166919c0786769.pos
-rw-rw-r-- 1 1001 1001 17M Nov 29 00:16 92f9621c4f3e41a6938ad65d2c37e969.pos
-rw-rw-r-- 1 1001 1001 42M Nov 28 23:29 103552f789714d07a2dff9f7143e001c.pos
-rw-rw-r-- 1 1001 1001 35M Nov 28 22:14 03578055b76b45bd961cf3931a0282d9.pos
-rw-rw-r-- 1 1001 1001 17M Nov 28 21:44 d908e24f73f04e83b85e679acf1d361b.pos
-rw-rw-r-- 1 1001 1001 13M Nov 29 00:32 b208026b097445c4a8eef6ea7dc6754e.pos
-rw-rw-r-- 1 1001 1001 15M Nov 29 00:24 dd957117dbf3437ca3cdb552b38cc8c4.pos
-rw-rw-r-- 1 1001 1001 9.4M Nov 29 00:37 ea6445abef914faeb767686e1c054987.pos
-rw-rw-r-- 1 1001 1001 2.5M Nov 29 00:38 87c0dd2f0577477ba233ee6a1c57c948.posNotice the size difference between the largest segment (42M) and the smallest segment (2.5M). By choosing the last segment we ended up picking the smallest segment, which explains our improved response time. If we query the first segment, which is much larger, we get a response in ~3 seconds. This is better then querying the whole index, but falls outside our stated reasonable query response time of 1 second.
Ideally, we want our segments to be balanced such that each Lambda in a fanout would return in under a 1 second. This requires customizing the merge policy, which is a large enough topic that it warants its own post. For now, we're going to assume that this is a solvable problem and focus on a design for the query Lambdas.
Let's take a look at a simple architecture that leverages what we've learned so far:
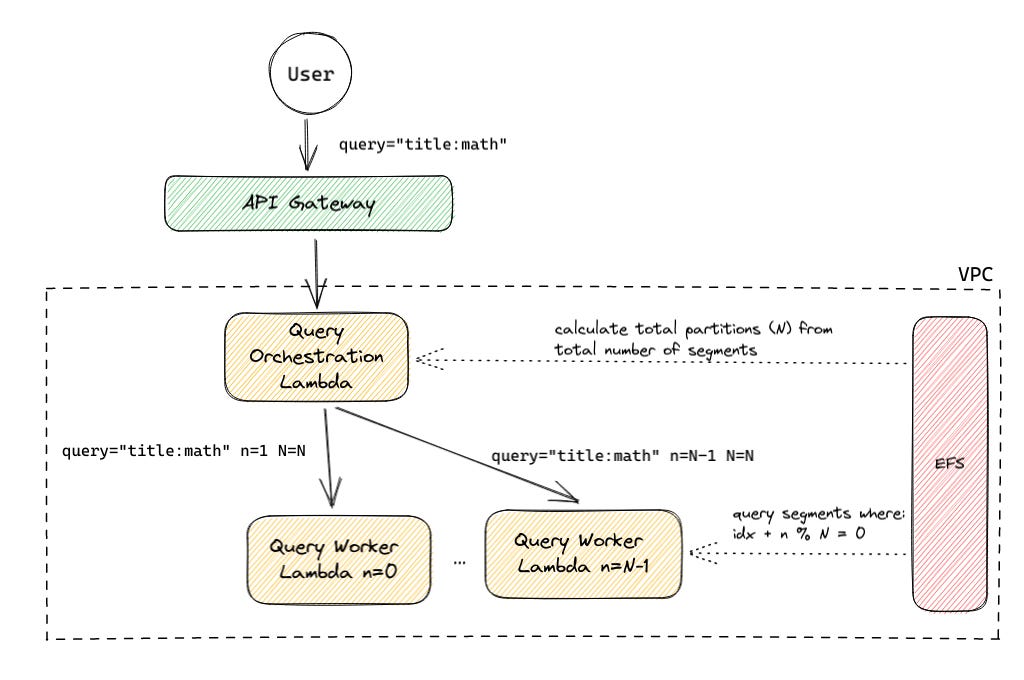
The query request comes in the exact same way as in the current straightforward approach, but instead of answering the query on its own, the initial orchestration Lambda fans out to N worker Lambdas that each run the exact same query against partition of segments. Before it does so, it calculates the desired number of partitions (N) from the segment metadata, optimizing N such that no Lambda has a data cold start latency greater than 1 second. Each Lambda then queries its partition and returns the result back the the orchestration Lambda. The orchestration lambda aggregates the top-K documents across all responses and returns the result back to the user — still pretty straightforward!
There are quite a few optimizations we can make on this simple architecture - such as improving the partitioning assignment to maximize the likelihood of segment cache hits on a worker - but this is a good enough starting point that can be iterated on in future posts and will be merged into Pathery soon. Additionally, this architecture will introduce some new problems with features such as pagination which will be addressed in a future post. For now, this is a good enough place to stop and gather feedback.