Pathery Dev Log #2: Indexing and the Document Store
Performance improvements thanks to a deep dive on Lucene/Tantivy indexing.

The latest version of Pathery (v0.1.1) has been released which includes performance improvements to querying and indexing latency. I was hoping to finish the distributed query implementation from the previous dev log in this update, but I ran into issues with the indexing worker and found a more fundamental optimization while addressing those issues which will be the focus of this update.
The issue that led me down this rabbit hole was a blocking one — the indexer was not able to index a 10,000-document subset of the testing data due to an ever-increasing indexing latency. Below you can see the IndexWriterWorker becoming slower as it indexes more documents until it eventually hits the timeout threshold.
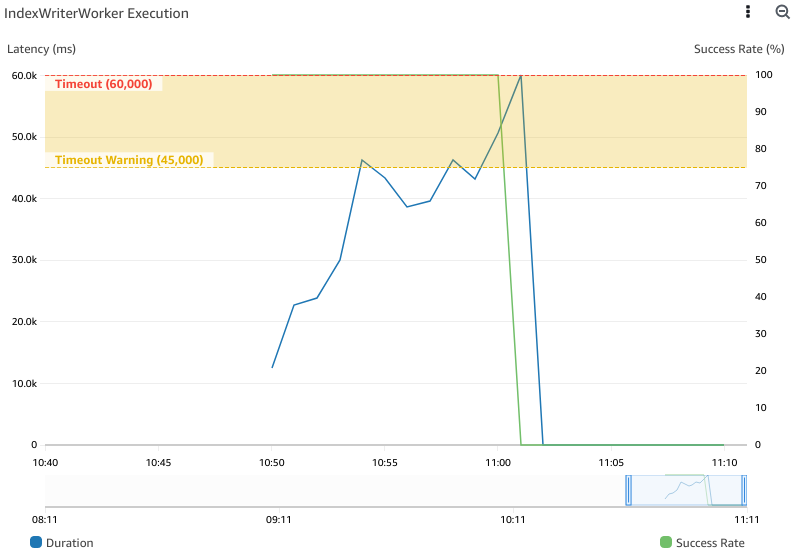
Making matters worse, once the IndexWriterWorker times out it fails to recover because of missing files in S3. To understand why this was happening, we need to understand the architecture that lead to this problem and how it relates to indexing at the low level.
Original Indexing Architecture
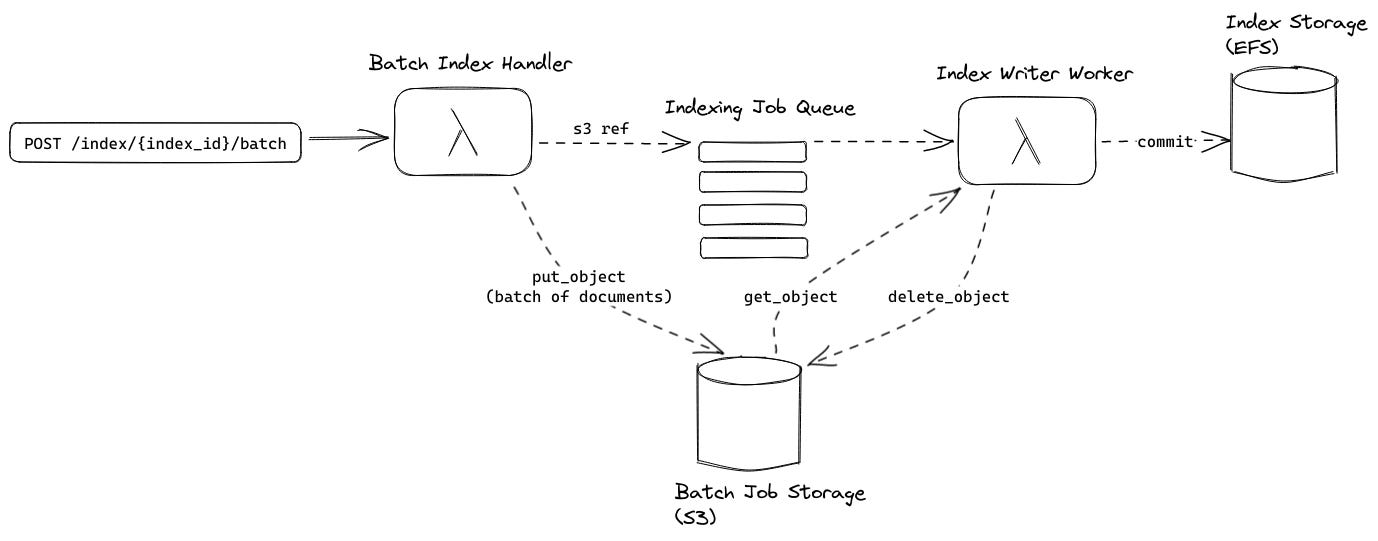
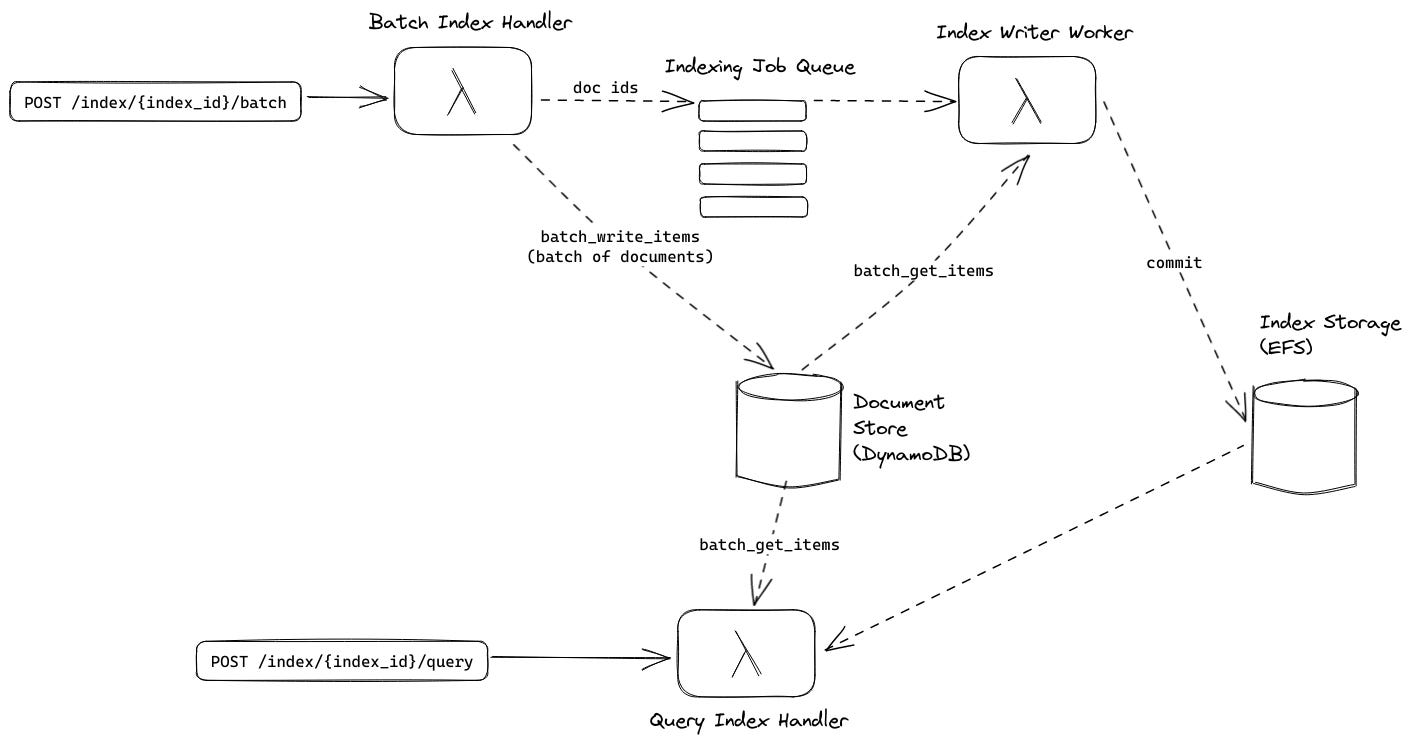
In the original architecture, a batch indexing request triggers BatchIndexHandler via the API Gateway which stores the documents contained in the request on S3 and places a reference to the S3 object containing the batch on a queue to be processed by the IndexWriterWorker. S3 is used in conjunction with the queue to increase the number of documents that can be processed in a single job (SQS has a payload limit of 256 KiB).
The IndexWriterWorker is decoupled from the BatchIndexHandler via an SQS FIFO queue. This FIFO queue serves two purposes:
Enforcing that one and only one
IndexWriterWorkeris active for a given index because index writing MUST be single-threaded to prevent corruption of the index.Batching multiple jobs to maximize the number of documents in a single
IndexWriterWorkerinvocation.
After processing a job from the job queue, the index writer worker commits a segment to the index storage and deletes the job from S3. This was the cause of the unrecoverable error mentioned in the intro. Multiple jobs are in a batch and the IndexWriterWorker deleted an S3 file every time a job was handled. When a batch failed due to timeout some job files had already been deleted and were not available for the retry.
The easy fix for this would be to move file deletion to the end of handling all jobs. However, this would not fix the ever-increasing execution duration which is the bottleneck for scaling to larger datasets. To fix this issue, we need to do a deep dive into the low-level index structure.
Index Structure Deep Dive
Tantivy structures its indexes as multiple (mostly) immutable segments. Each segment is itself a queryable index which was discussed in the previous dev log. A segment is composed of multiple segment files, each of which has a structure that is optimized for answering different types of queries. Different segment files have different file extensions (e.g. .idx, .pos, .store, etc.).
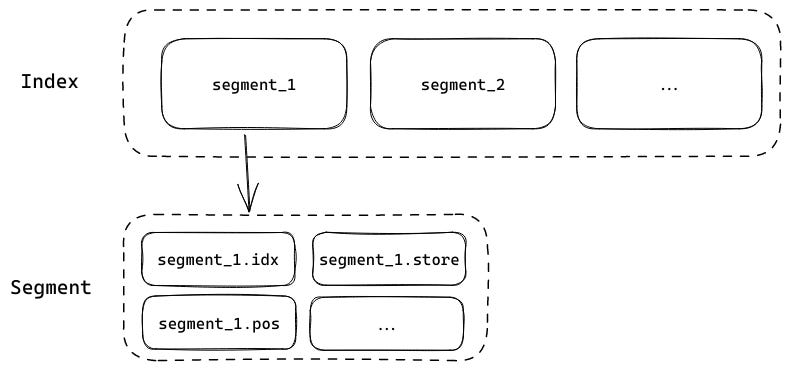
When an IndexWriter indexes new documents it does so in memory, creating temporary files in RAM for a new segment. When you want to persist this new segment, you call commit on the IndexWriter and the in-memory files are flushed to the underlying filesystem.
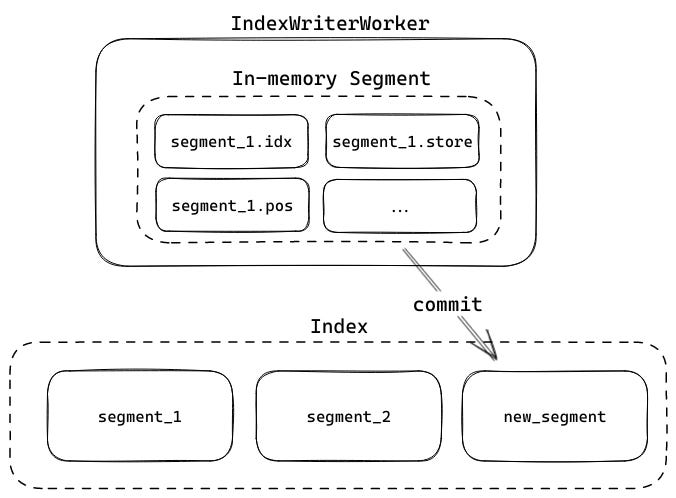
Once a segment is committed to the filesystem, it cannot be edited. This allows the index to be queried without worrying about new files being added to a segment while the query is executing. The tradeoff of segments not being editable is that the only way to add new documents is to append new segments.
This eventually leads to a proliferation of files — for example, if you called commit after every document you indexed, you would end up with one segment per document which would be inefficient to search. Tantivy solves this problem by periodically merging smaller segments into larger segments. This reduces the number of segments, increasing the efficiency of the search process.
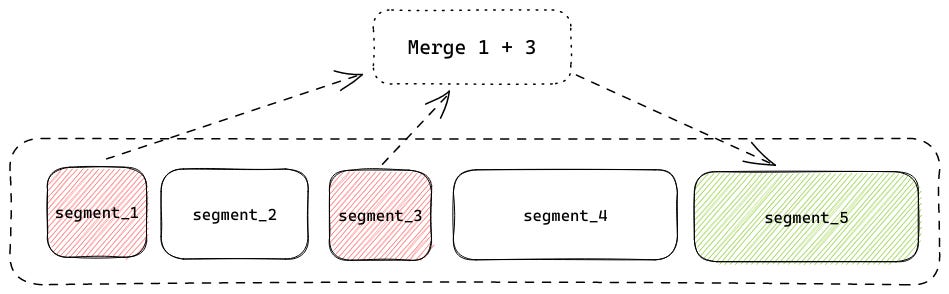
In the example above, segment_1 and segment_3 are merged to form a new segment, segment_5. segment_1 and segment_3 are deleted after the merge, reducing the number of segments. Because merging causes segments to be deleted, segments are not fully immutable. This is also what forces the single-threaded constraint on writers — if two writers try to merge conflicting segments, the index will become corrupted.
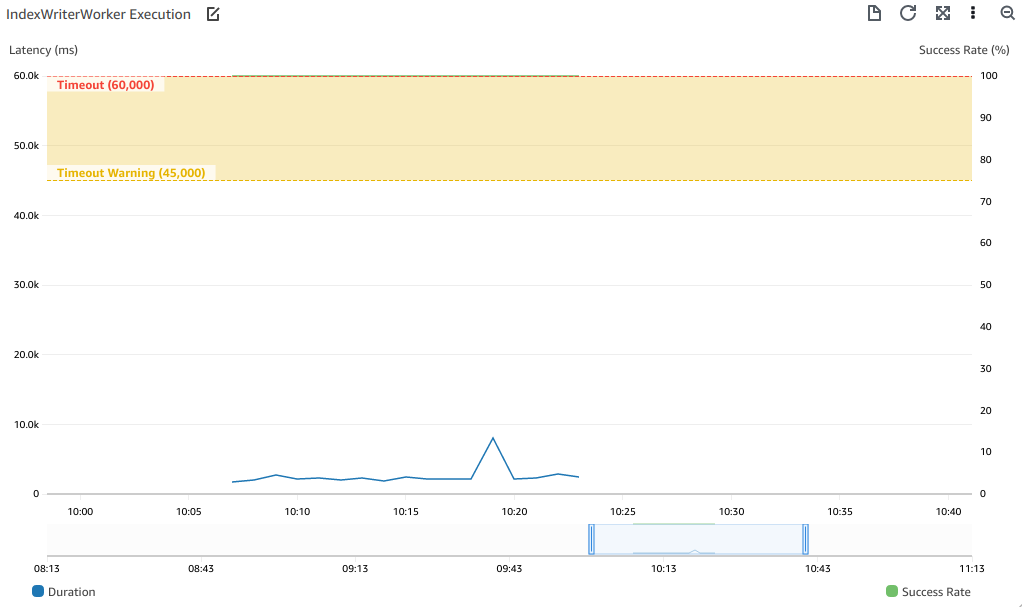
As an index grows, the merging operation becomes more expensive. The larger a segment is, the longer it takes to merge with another segment. This is especially expensive in an environment with EFS and Lambda as merged files need to be read from the network and subsequently written over the network. You can see this below on the maximum execution duration graph for the IndexWriterWorker when generating a large index.
Luckily, Tantivy lets us configure the maximum number of documents a segment can contain for it to be considered for merging. By lowering this value we can smooth these peaks and drastically improve our indexing throughput. But even in the best case, batches are taking far too long to index (>10s per execution). Perhaps there is another property of the index structure we can take advantage of to improve performance across the board.
Because they store different representations of the data, some segment components are larger than others. Below you can see the files that constitute one of the larger segments in the index.
11K Nov 29 00:34 dd957117dbf3437ca3cdb552b38cc8c4.15628857.del
99 Nov 29 00:24 dd957117dbf3437ca3cdb552b38cc8c4.fast
571K Nov 29 00:24 dd957117dbf3437ca3cdb552b38cc8c4.fieldnorm
16M Nov 29 00:24 dd957117dbf3437ca3cdb552b38cc8c4.idx
15M Nov 29 00:24 dd957117dbf3437ca3cdb552b38cc8c4.pos
58M Nov 29 00:24 dd957117dbf3437ca3cdb552b38cc8c4.store
4.9M Nov 29 00:24 dd957117dbf3437ca3cdb552b38cc8c4.termThe .store file is significantly larger than the rest, this is because it stores the original document that was indexed in its entirety. The original file is stored because it is needed to generate highlights in the query response which helps users understand what parts of a document matched a query. The JSON below is an example document match for the query “math”, note the HTML highlights in the snippets object.
{
"doc": {
...
},
"score": 10.876168,
"snippets": {
"author": "<b>Math</b> Buck, Dominiek Beckers, Susan S. Adler (auth",
"description": "Mit diesem Buch ist es Dominiek Beckers und <b>Math</b> Buck (Rehabilitationszentrum Hoensbroek) gelungen, fur Physiotherapeuten, die mit dem PNF-Konzept"
}
}The .store file causes a significant performance hit when querying in addition to indexing. This is because it is stored in a compressed format which requires the full file to be pulled to retrieve any document contained within the .store component. If we could store original documents outside of the index it would substantially improve indexing and query performance.
Introducing the Document Store
If only there was a pay-per-use AWS service that allowed you to read and write JSON documents by id efficiently…

Oh yeah, that’s right — that’s DynamoDB’s jam. DynamoDB is ideal for storing and retrieving JSON payloads by id. We could update the query Lambda to retrieve the original payload by document id from a DynamoDB table and tell Tantivy to not store the original document.
This is the crux of the latest PR that was just merged, a new DynamoDB-backed Document Store was introduced, the ability to tell Tantivy to store original documents was removed, and the query Lambda was updated to use the DocumentStore to generate highlights. Additionally, the S3 job store was removed since the BatchIndexHandler could write documents to the document store directly since that operation no longer requires access to the index on EFS. This removes the cause of the unrecoverable error mentioned in the intro.
With the new Document Store in place, we can update the original architecture diagram to complete the picture for our new architecture:
And with that, we fixed the bug that led us down this rabbit hole in a way that would make Hal fixing a lightbulb proud. But, was the excursion worth the effort? Let’s re-index the data that generated the graph above and see.
Wow, that is significantly better! Our best-case performance now tops out at around 2 seconds and we just have one large peak (probably due to a large merge). Additionally, the graph does not slope upward significantly as the index grows so it should be safe to scale well past 10,000 docs on the indexing side.
That wraps things up for this update. Next time we’ll revisit query performance and see if we can scale query latency as our index grows (assuming I don’t fall down another rabbit hole). Thanks for reading.